Desarrollo técnico aplicando la inteligencia artificial de ChatGPT en la búsqueda de información oficial con Oficius
Publicado el 15 de mayo de 2025 por Manu Pijierro
¡Hola!, muchas gracias por venir hasta aquí. Si sigues leyendo, te voy a contar los detalles técnicos sobre cómo he llegado a integrar Oficius y ChatGPT para mejorar las búsquedas de información oficial en boletines oficiales de España.
Inciso: También escribí un artículo explicando para un usuario 'normal' cómo funciona, qué se puede esperar de esta integración y qué no. Si te interesa, puedes leerlo en el siguiente enlace: leer el artículo.
Lo que te cuento en este artículo
- Partiendo de Cero, contexto personal.
- Primera iteración: GPT personalizado.
- Segunda iteración: GPT personalizado pero desde Oficius.
- Tercera iteración: Búsqueda de anuncios con vector embeddings.
- Aprendizajes
- ¿Me ayudas?
Partiendo de cero, contexto personal
Antes de nada, te cuento el origen de toda esta película y las motivaciones principales de esta integración. Si eres desarrollador de software (y más si eres autónomo), quizás me entiendas.
Verás, desde que apareció la inteligencia artificial, como la mayoría de las personas del sector tecnológico, he estado muy interesado en su desarrollo y en las posibilidades que ofrece.
Si bien es cierto que soy usuario de ChatGPT desde el minuto cero, desconocía toda esa parte de desarrollo y de integración de la inteligencia
artificial en aplicaciones de terceros.
En distintas charlas, conferencias y reuniones con otros colegas de profesión, no hacía más que escuchar a la gente hablar de la inteligencia artificial y cómo lo aplicaban en productos y clientes
(que luego, tampoco es tan así, que tampoco hay un uso tan masivo...pero bueno, esto es harina de otro costal...), y a mí,
todo eso, me generó una presión añadida con una idea recurrente: -tengo que aprender...tengo que ponerme ya...tengo que estudiar...blablablabla...te vas a quedar atrás...están
todos a tope...blablabla...- Lo típico de la exigencia implacable con uno mismo, un drama si no se controla, lo sabes, ¿no?
Sigamos. El 28 de febrero de este año 2025, di una charla NO técnica en el Ateneo de Fregenal de la Sierra (Badajoz) sobre inteligencia artificial. Un éxito,
todo sea dicho, que mi trabajo me costó. Como digo, la temática no era técnica (no me veo yo ni con el conocimiento ni la vergüenza suficiente de ir dando charlas técnicas sobre inteligencia artificial por ahí),
sino más bien un
acercamiento para todo tipo de personas sobre qué es toda esta revolución tecnológica, sus aplicaciones, riesgos, oportunidades, filosofía, etc.
Lógicamente, tuve que prepararme la charla...y para eso, desde un mes antes, estuve leyendo mucho y escuchando mucho podcast sobre todo este mundo artificial.
Entre los podcast que escuché, me encontré con
un divulgador llamado Jon Hernández que me pareció muy interesante.
Jon, tiene el Club de la IA, un club privado de personas
interesadas en este tema. Me apunté y ahí sigo aún. Una vez dentro, vi que tenían un curso de GPTs personalizados y me pareció interesante como punto de partida para iniciarme en este mundo.
Valoraba de todo, tanto el club como el curso, que me quitaban mucha morralla de la que yo iba a tener que leer si fuera por mi cuenta. Iban al grano.
Así que todo comenzó ahí. Partiendo de GPTs personalizados las puertas comenzaron a abrirse y luego ha sido ir tirando del hilo. En mi opinión, desde el punto de vista técnico va todo demasiado rápido, es una temática inmensamente amplia, absolutamente transversal y es muy difícil, por no decir imposible, seguir el ritmo. Pero mira, hasta donde lleguemos y ya está.
Primera iteración: GPT personalizado
Spoiler: como habrás leído anteriormente, he partido de cero en todo este proceso. Tanto en conocimiento como en práctica. Seguramente, habrá cosas que se podrían haber planteado mucho mejor. No tomes todo lo que cuento al pie de letra como lo más óptimo como si yo fuera un experto en la materia, simplemente ha sido mi camino. Si realizas alguna crítica, que sea constructiva, por favor, que si no, me hundes en la miseria más absoluta y haces que me retire a un huerto (lo cual tampoco me parece tan mala idea, la verdad...), aún así, estaré encantado de recibirla y poder mejorar. Al lío.
Objetivo primera iteración: conectar de alguna forma ChatGPT con Oficius.
Todo comenzó creando un primer GPT personalizado. ¿Qué es esto de los GPTs personalizados? Por si no lo conoces, básicamente es hacerte un ChatGPT a la medida dentro del propio ChatGPT. Hay varios acercamientos a la hora de llevarlos a cabo. Puedes hacer un GPT personalizado desde cero, es decir, tú le dices a ChatGPT lo que quieres que haga de forma específica y él lo hace (o se supone), aplicándole un prompt (dándole órdenes, básicamente), y un comportamiento específico. También, puedes crear un GPT personalizado que no solo tenga el conocimiento de ChatGPT, sino que además tenga acceso a información que sea de tu interés, como archivos subidos directamente o, y aquí viene lo interesante, acceso a información externa como una base de datos o un API o lo que sea y pueda interactuar con ella.
 Con estas, creé
DOE-GPT
un GPT personalizado que tiene acceso a un API de Oficius que desarrollé expresamente para él. ¿Cómo funciona?
A nivel usuario, le preguntas lo que sea por un boletín y día y ChatGPT lo resuelve como estime oportuno, no hay mucho misterio.
Con estas, creé
DOE-GPT
un GPT personalizado que tiene acceso a un API de Oficius que desarrollé expresamente para él. ¿Cómo funciona?
A nivel usuario, le preguntas lo que sea por un boletín y día y ChatGPT lo resuelve como estime oportuno, no hay mucho misterio.
A nivel técnico, lo primero es definir un prompt adecuado para que ChatGPT extraiga los parámetros de
búsqueda que posteriormente son pasados al API de Oficius. No te creas, escribir un buen prompt tiene su arte.
De hecho, creo que hay gente que se dedica solo a esto.
Lo segundo, fue definir una acción. En mi caso, la acción no es más que la definición sobre cómo se va a comunicar ChatGPT con el API de
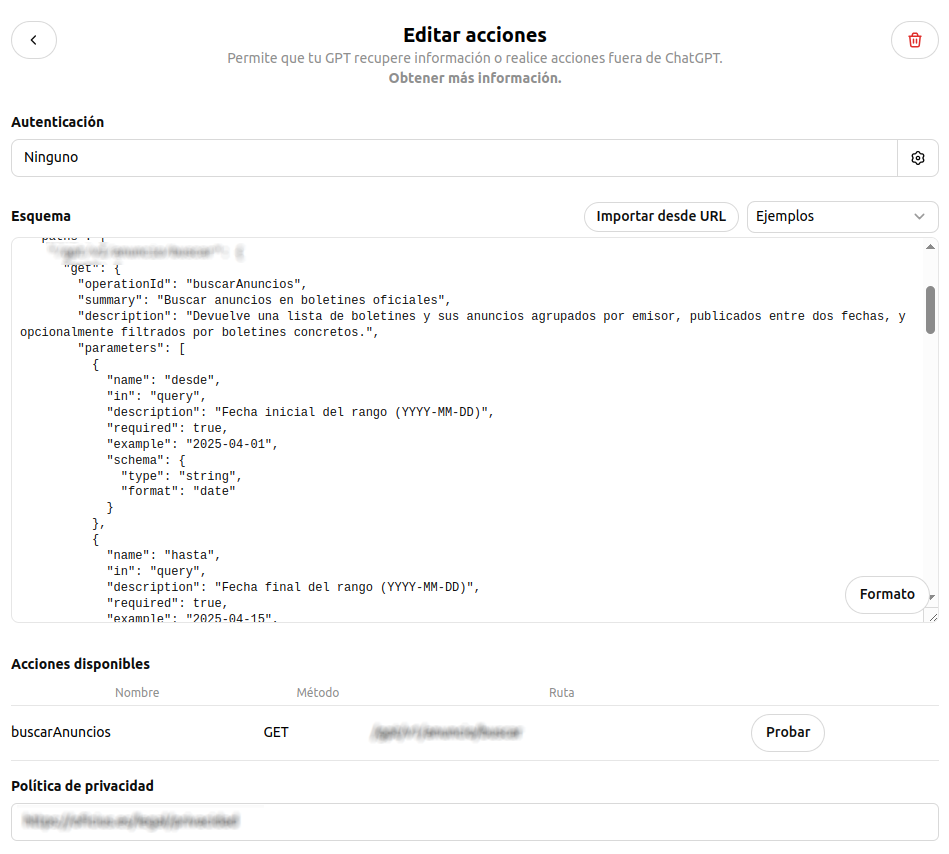
Oficius. Se trata de definirle un esquema basado en Open API
para saber cuál es el
formato de la petición que se le va a hacer al API y cómo se va a recibir la respuesta. Es un JSON estructurado de cierta forma en el que se especifica absolutamente todo: url de la petición,
formato que debe tener la petición al API y formato esperado de respuesta para que lo analice ChatGPT.
A continuación puedes ver el JSON que estructura la petición que se le hace al API de Oficius. Mientras más específica sea la forma de indicar los parámetros, mejor será la extracción de los mismos.
 Haz click en la imagen para verla más grande
Haz click en la imagen para verla más grande
También puedes ver el formato de la respuesta esperado por ChatGPT
 Haz click en la imagen para verla más grande
Haz click en la imagen para verla más grande
¿Qué aprendí con todo esto?: lo más básico fue crear GPTs personalizados y poder comunicarlos con un servicio de terceros.
¿Qué nivel de dificultad tiene? No mucho. Es verdad que si el servicio es tuyo tienes que implementar el API, desde luego, pero después
todo lo que es la definición de la acción, el esquema o incluso el prompt, te ayuda mucho el propio ChatGPT.
Segunda iteración: GPT personalizado pero desde Oficius
Objetivo segunda iteración: conectar de alguna forma Oficius con ChatGPT.
Bien. Una vez conseguida la comunicación entre ChatGPT y Oficius, el siguiente paso fue hacer lo contrario, es decir, que Oficius pudiera comunicarse con ChatGPT a través de su API.
Lo primero es darse de alta en la plataforma de desarrollo de OpenAI y crear una clave de API. Esto es lo más sencillo, al menos en su configuración básica para mis necesidades.
Ojo, que esto es importante, usar el API cuesta perras, vamos, que cuesta dinero, money, euros, ya me entiendes.
Desde el punto de vista de la implementación, no es muy complicado porque el mismo ChatGPT te ayuda a implementar el mínimo caso de uso. En mi caso, usando PHP, era algo similar a lo siguiente:
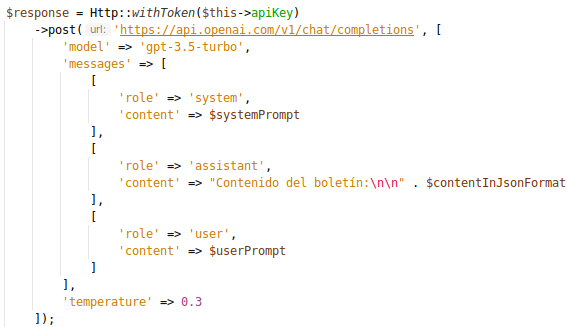 Ejemplo de petición al API de OpenAI
Ejemplo de petición al API de OpenAI
¿Qué hace la petición anterior? es mi caso más básico y tiene que ver con la petición que le hago a ChatGPT para solicitar el resumen
de un boletín de un día (en realidad, hace un resumen o lo que sea que vaya en el mensaje del usuario).
¿Cómo funciona? Una vez seleccionado el boletín y el día, Oficius le pasa a
ChatGPT en formato JSON todo el listado de los anuncios publicados en ese boletín y día. Ojo, esto es mucha información, después te cuento las consecuencias.
Como ves en la imagen, se configuran tres roles o perfiles: el sistema, el asistente y el usuario. El sistema es el que le dice a ChatGPT lo que tiene que hacer y
como se tiene que comportar, el asistente es el que recibe la información de los anuncios y el usuario es el que hace la pregunta y lo que quiere realmente con ese contenido.
¿Qué aprendí con todo esto?: A comunicarme con el API de ChatGPT y, lo más importante, comprender e interiorizar que se le puede pedir
y como. No es algo tan inmediato.
¿Qué nivel de dificultad tiene? Regulero. Técnicamente, no mucho, lo más complejo quizás es definir correctamente los prompts para que ChatGPT haga correctamente lo que debe.
Un ejemplo tonto que me llevó un buen rato entender cómo funciona. Yo le preguntaba por resúmenes de boletines y de días concretos. A veces, le especificaba
el día no de forma exacta, es decir, le decía "el lunes pasado" o "el lunes de la semana pasada" y no me lo entendía por lo que me daba un resumen equivocado.
En cambio, si le decía "el 1 de marzo de 2025" sí que me lo entendía. ¿Solución? en el prompt del sistema, indicarla la fecha actual para darle contexto y que él supiera traducir luego
"el lunes pasado" a una fecha específica. A mí me parecía obvio preguntarle por una fecha "el lunes pasado" y que lo tuviera que saber pero después de encontrarme con este problema pensé
¿y por qué habría de saberlo? esto cambió mi concepción de lo que se debe especificar a ChatGPT, que básicamente es todo y mientras más específico sin presuponer nada, mejor.
SOBRE EL COSTE DEL USO DEL API
Lo anterior funciona razonablemente bien, pero hay un problema, al menos para mí. En el primer ejemplo que hice resultó muy caro, pero ¿por qué? te preguntarás. Pues por dos cosas fundamentales que me hicieron cambiar mi visión sobre cómo funcionaba todo esto y el coste que podía tener.
Lo primero es entender realmente el coste que tiene ChatGPT. De manera muy simple, te cobra por tokens (que son palabras o partes de palabras) tanto de entrada (lo que tú le pasas) como de salida (el resultado que te devuelve). Además, hay que tener en cuenta el modelo utilizado, es decir, con qué sistema de inteligencia artificial estás trabajando. Yo al principio tenía configurado el modelo gpt-4-turbo, el mejor modelo...pero también el más caro. Una ruina para mi caso de uso. ¿Por qué? pues porque la información oficial es muy amplia, es mucho contenido. Un listado de anuncios de un boletín como el DOE de un día cualquiera puede tener entre 10 y 50 anuncios, y cada anuncio pueden ser como el siguiente ejemplo:
Nombramientos.- Resolución de 28 de abril de 2025, de la Dirección General de Recursos Humanos, por la que se nombra personal estatutario fijo a la aspirante que ha superado el proceso selectivo excepcional de estabilización por el sistema de concurso, convocado por Resolución de fecha 20 de diciembre de 2022, en la Categoría de Enfemero/a, en las instituciones sanitarias del Servicio Extremeño de Salud.
Un anuncio como el anterior, multiplicado por 10, 20, 30...suma una cantidad de información brutal. Si a eso le sumas que el modelo gpt-4-turbo es el más caro, pues ya tienes la ruina asegurada.
 Ejemplo de coste de una llamada al API.
Ejemplo de coste de una llamada al API.
La imagen anterior es una muestra del drama, del motivo por el que mi cara se quedó blanca del susto que me dio. Una única petición, una sola, tuvo un coste de 0,33 céntimos de dólar (más o menos de euro también). 33 céntimos. 1 petición. 33 céntimos. Acho, que me quedé a cuadros.
Así que, viendo el panorama, lo que hice fue buscar formas de optimizar y hacer más barata cada petición, ¿qué hice? pues lo siguiente;
- Lo primero fue cambiar el modelo pasando a gpt-3.5-turbo que es el más barato y para hacer resúmenes, comprender texto y demás, funciona muy bien.
- Lo segundo fue cambiar el formato de salida. En el ejemplo, el prompt del sistema le decía a ChatGPT que devolveria el formato en un html enriquecido con emojis, colorines...vamos, todo bien bonito para el usuario. Lo cambié a formato markdown. Que sí, que no es tan bonito pero tampoco estamos ahora para lucirnos, el caso es que funcione. El número de tokens de salida con este cambio también fue bastante positivo.
- Lo tercero fue implementar una caché interna. Cada vez que se solicita el resumen de un boletín y un día, si ya se pidió anteriormente, no se vuelve a pedir a ChatGPT sino que se devuelve el resultado de la caché.
- Lo cuarto fue buscar un apoyo externo, en este caso, Academia Maestre se ofreció a ayudarme con el coste de la implementación y el uso del API. Son clientes míos desde hace más de 10 años y hay confianza mutua para estas cosas. Gracias desde aquí.
Tercera iteración: Búsqueda de anuncios con vector embeddings
Objetivo tercera iteración: realizar búsquedas semánticas de anuncios a través de ChatGPT.
Vamos a comenzar por exponer las dos limitaciones principales en las que nos encontramos en este punto del desarrollo en la búsqueda de información oficial en Oficius:
- Por un lado, las soluciones anteriores de búsqueda de información estaban limitadas a especificar un boletín y un día y, a partir de ahí, que ChatGPT comenzara su análisis y resultados...además del coste, claro.
- Por otro lado, el sistema de búsqueda de Oficius siempre ha estado basado en el uso de palabras clave. Es decir, para buscar anuncios, tenías que introducir las palabras que creyeras iban a estar incluidas en los anuncios de tu interés. Esto es simple pero cuando trabajas con información oficial puede no resultar muy obvio saber qué palabras hay que usar para que concuerden con las expresadas en términos oficiales.
¿Qué solución quería encontrar? Mi sueño para mis buscadores en boletines oficiales siempre ha sido poder buscar y encontrar información oficial de forma semántica, es decir, que no tuviera que especificar las palabras clave exactas que quería buscar, sino que pudiera buscar de forma más natural, como si le estuviera hablando a una persona.
VECTOR EMBEDDINGS
¿Qué es esta movida de los vector embeddings?
Pues es una forma de representar el texto en un espacio vectorial.
Es decir, cada palabra o frase se convierte en un vector de números que representa su significado.
La distancia entre dos vectores mide su grado de relación.
Las distancias pequeñas indican un alto grado de relación, mientras que las grandes indican un bajo grado de relación.
Tampoco me pidas mucha más explicación porque tampoco es que sea un experto en la materia.
Si eso, le preguntas a ChatGPT y él te lo explica mejor que yo, seguro. A mí, como la mayoría de las cosas relacionadas con inteligencia artificial, me sigue
pareciendo magia.
Para saber más sobre esto, puedes acceder a la
documentación oficial de OpenAI .
Arquitectura necesaria
Hasta el momento, la arquitectura de toda la comunicación entre Oficius y ChatGPT era la siguiente:
Por un lado, mi plataforma con Oficius escrito en PHP y una base de datos
MySql. Por otro, ChatGPT con su API.
Ha sido necesario incluir una nueva base de datos. En este caso, una base de datos PostgreSQL con la extensión pgvector para poder guardar la relación entre los anuncios y sus vector embeddings. MySql no tiene esta extensión.
Ahora, la información de los anuncios se guarda en la base de datos de Oficius como siempre y, además, conforme se generen los vector embeddings de cada anuncio se van guardando en la nueva base de datos PostgreSQL. En esta base de datos, para cada anuncio, se almacena su id (para mantener la correspondencia), su vector embedding, fecha de publicación y el id del boletín al que pertenece para facilitar la búsqueda de anuncios en base a un posible filtrado.
¿Cómo se genera los vector embeedings?
Nuevamente, para este proceso, vamos a hacer uso del API de ChatGPT. En este caso, la petición es muy sencilla y no tiene mucho misterio.
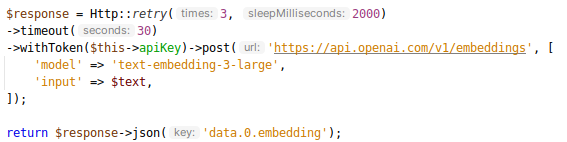 Ejemplo de petición al API de OpenAI para generar un vector embedding
Ejemplo de petición al API de OpenAI para generar un vector embedding
Como ves, hay un campo input que recibe el texto para convertirlo en un vector embedding. El campo model
es el modelo de inteligencia artificial que se va a utilizar para generar el vector embedding. Hay dos, el text-embedding-3-small y
text-embedding-3-large, ¿La diferencia? básicamente que el modelo large es más preciso y potente
y captura mejor el significado de los textos. En el caso de Oficius con textos legales y oficiales esto es algo muy importante.
El modelo large también es más caro. El coste de la petición es de aproximadamente 0,0001 céntimos de dólar
por cada 1000 tokens o alguna ridiculez similar, algo que para mi contexto y cantidad de datos (y mira que hay datos), es absolutamente irrelevante. En este caso no me arruino.
Inicialización el sistema
Lo primero que hay que hacer es inicializar el sistema.
Una vez configurada la nueva base de datos PostgreSQL y la tabla que va a almacenar los anuncios y sus vector embeddings, lo que hice
fue recorrer los anuncios de la base de datos de Oficius y generar los vector embeddings de cada anuncio para guardarlos.
El típico comando de sistema que lo dejas ejecutando varias horas. Para que te hagas una idea del coste, la generación de los vector embeddings de unos 30.000 anuncios
apenas me ha supuesto unos céntimos. ¿Por qué es tan barato? te preguntarás. Pues porque básicamente es una tarea muy sencilla para OpenAI y no requiere de un gran esfuerzo computacional.
¿Cómo es el proceso de búsqueda de anuncios?
Voy a explicar, con palabras, como sería el flujo para trabajar con vector embeddings en la búsqueda de anuncios:
- Lo primero, lo dicho anteriormente, tener una base de datos con todos los vector embeddings de los anuncios generados.
-
El usuario hace una búsqueda, pongamos por ejemplo
"empleos de enterrador en el doe el último mes". Sí, la búsqueda es un poco chunga pero tiene que
haber de todo. En esta búsqueda, y he aquí algo muy importante, se diferencian tres partes:
- La búsqueda de la palabra clave "empleos de enterrador".
- La búsqueda del boletín "DOE".
- La búsqueda del periodo de tiempo "último mes".
- Con esa cadena de búsqueda completa, hacemos una primera llamada al API de ChatGPT para que nos desgrane su contenido y obtener palabras clave, en este caso, "empleo enterrador" y los filtros o parametros de búsqueda que se van a aplicar: el boletín y el periodo de tiempo, como un rango de fechas 'inicio' y 'fin. Aquí, lo complicado está en la configuración del prompt para que ChatGPT entienda lo que le estamos pidiendo y nos devuelva la información de forma estructurada. Actualmente, casi siempre lo hace bien.
- Una vez nos devuelve la información estructurada, la pasamos las palabras obtenidas anteriormente a un segundo API de ChatGPT para que nos devuelva el vector embedding asociado.
- Ahora que ya tenemos el vector embedding de la búsqueda, lo que hacemos es buscar en la base de datos PostgreSQL de Oficius los anuncios que tengan un vector embedding similar al de la búsqueda. Recordemos que mientras menor es la diferencia, mayor es la relación entre ambos textos. Para ello, se utiliza la función pgvector de PostgreSQL que permite calcular la distancia entre dos vectores. Tengo establecido que la distancia máxima entre el vector de búsqueda y el de los anuncios sea de 2. Esto significa que si la distancia es menor a 2, se considera que ambos vectores son similares. Valores más altos no tienen sentido porque la relación entre ambos textos es muy baja. En este caso, el resultado de la búsqueda sería nulo. Además, se le pasa a la función de búsqueda el resto de parámetros obtenidos anteriormente: boletín y rango de fechas. De esta forma, se filtran los resultados obtenidos junto con el vector embedding.
- La búsqueda anterior nos va a devolver una lista de ids de anuncios. El siguiente paso será buscar en la base de datos de Oficius los anuncios que tengan esos ids para mostrarlos en pantalla.
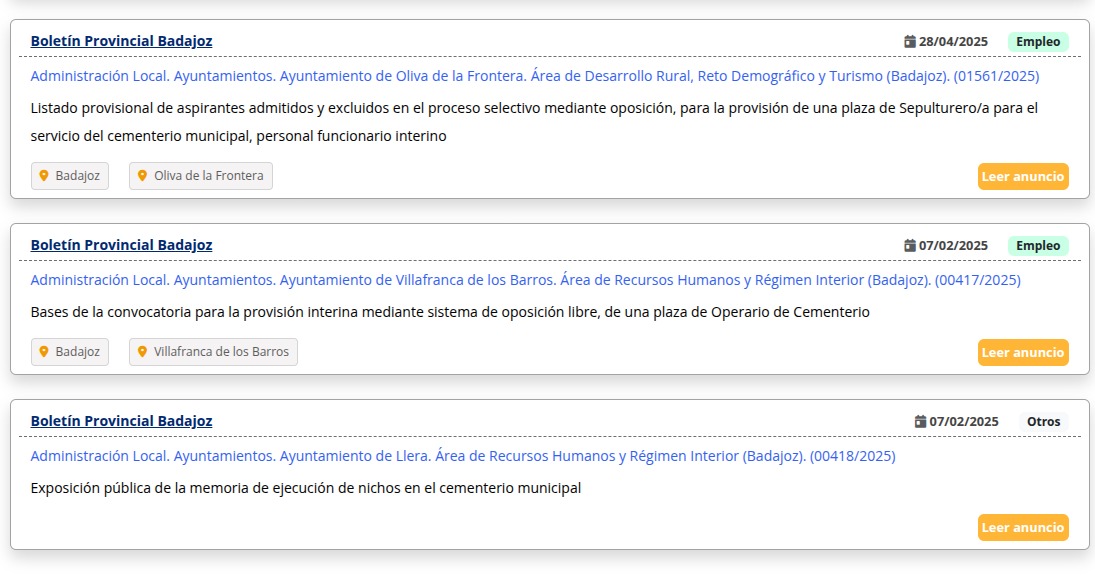
A continuación puedes ver un ejemplo de búsqueda semántica similar a la del ejemplo. En este caso, la búsqueda es "empleos de enterrador en la provincia de Badajoz".
Como puedes ver, los resultados devueltos son anuncios de empleo relacionados con la búsqueda realizada.
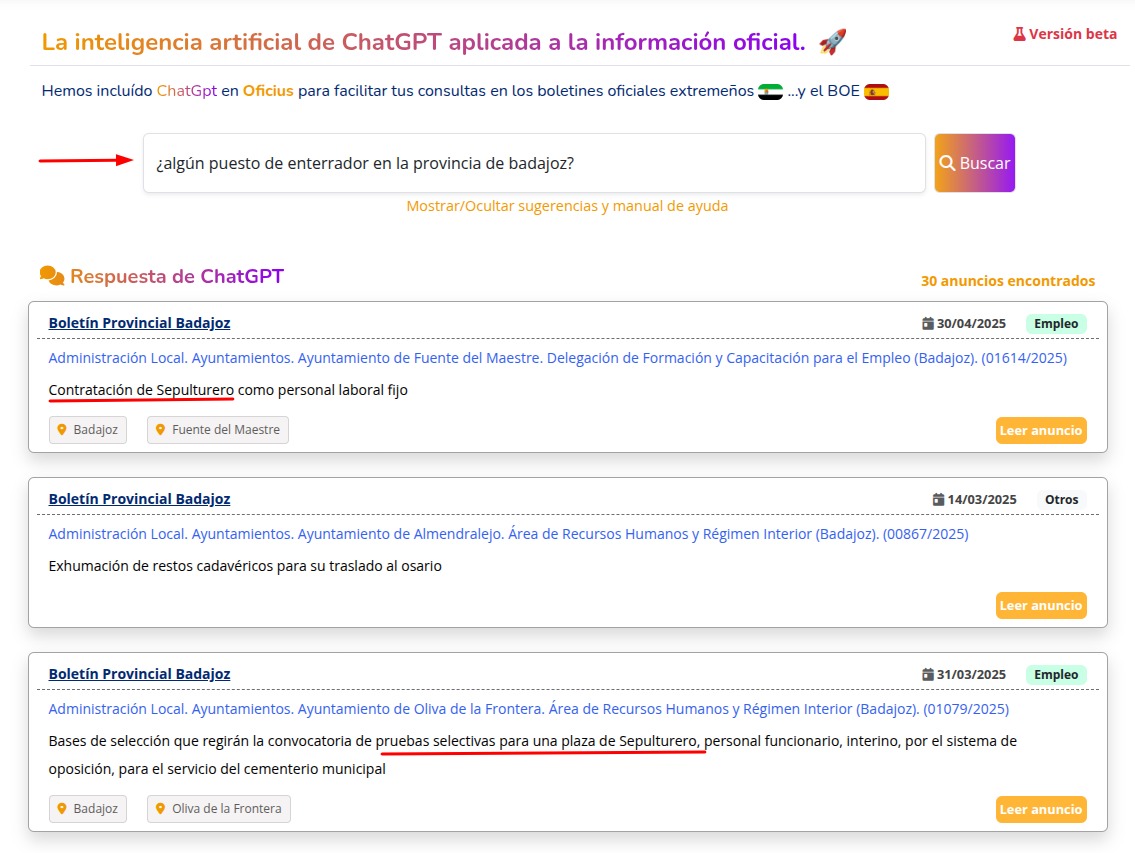
 Haz click en la imagen para hacerla más grande
Haz click en la imagen para hacerla más grande
En resumen: un usuario hace una búsqueda. De esta búsqueda, ChatGPT extrae las palabras clave y los filtros de búsqueda. Con esas palabras clave, se genera un vector embedding gracias también a ChatGPT. Ese vector embedding se busca en la base de datos PostgreSQL de Oficius para encontrar los anuncios que tengan un vector embedding similar al de la búsqueda. Se obtiene una lista de ids de anuncios que se buscan en la base de datos de Oficius para mostrarlos al usuario.
Qué, ¿cómo te has quedado?, ¿más o menos? La verdad, lo tengo hecho, funciona y funciona, pero no podría decir al 100% que es la mejor y más óptima forma de hacer este tipo de búsquedas. Si tienes alguna idea mejor, házmela llegar. Gracias por adelantado.
¿Qué nivel de dificultad tiene? Alto, al menos para mí. Tener que instalar y configurar una nueva base de datos, comprender el funcionamiento de los
vector embedding, generarlos y buscar la forma más óptima de consultar la base de datos para obtener los resultados deseados no es algo trivial.
La parte de la búsqueda semántica es un poco más complicada porque tienes que entender cómo funciona el API de ChatGPT y cómo
se generan los vector embedding y aplicarlos a la búsqueda puees....fácil e inmediato no es, desde luego.
¿Qué he aprendido con todo esto? Yo que sé, muchas cosas. Leyendo todo lo de arriba se puede inferir el aprendizaje.
Pero, lo mejor, es que tal y comenté al comienzo de esta sección, he conseguido mi sueño de implementar una herramienta que permite búsquedas semánticas para encontrar información oficial.
Aprendizajes
¿Qué he aprendido con todo este proceso? Bien, pues lo primero es meter cabeza de una vez por todas en el mundo de la inteligencia artificial y su desarrollo
personalizado. Tengo un plan sobre cómo seguir avanzando en este sentido y conforme vaya teniendo tiempo lo iré llevando a cabo.
También, me ha hecho ver los límites de la inteligencia artificial y lo que se puede hacer con ella, al menos hasta donde yo llego y
en los casos de uso que tenía en mente. No todos los casos de uso que yo tenía en mente son factibles por el coste que tienen.
Ahora mismo, sé mucho mejor que hace un par de meses lo que se puede hacer y lo que no. Me ha sido muy útil porque ahora sé cómo puedo aplicar todo lo aprendido a algunos de mis clientes.
Que, en verdad, era el origen de todo esto. ¿Cómo puedo aplicar la inteligencia artificial a mis clientes? ¿Qué casos de uso puedo implementar para ellos? Ahora, tengo todo esto mucho
más claro.
En lo personal.
Al final como siempre, más complicado de lo que me parecía en un principio y echando muchas más horas de las planeadas.
Mis estimaciones optimistas de tiempo y esfuerzo saltaron por los aires nuevamente. Lo que iba a ser un acercamiento a usar
inteligencia artificial con información oficial se ha convertido en un subproyecto dentro de Oficius. Siempre pico. Siempre me animo y luego ¡plaf!, termino
bastante cansado del esfuerzo. Porque no solo es aprender a implementar algo totalmente nuevo, sino que además tienes que implementarlo, hacerlo bien o, al menos,
medianamente bien, decente, y ponerlo en producción. Y todo eso implica hacer muchas cosas en el proyecto. Programar más cosas de las previstas, por ejemplo: implementar una caché
para los resúmenes, implementar un sistema de opinión de las respuestas, aplicar cierta usabilidad en el frontend, dejarlo todo que se vea más o menos bonito, etc.
Ah, y además, documentar todo lo que haces para que el resto del mundo
sepa qué has hecho y como se usa. Redactar la información de la página, el manual de uso o incluso los dos artículos que he escrito en el blog sobre este desarrollo me han llevado
horas. Horas que me quito de mi trabajo y que me generan un esfuerzo adicional y un estrés que no me gusta nada, la verdad.
¿Contento? Sí, claro...pero a veces pienso que es demasiado esfuerzo...
¿Me ayudas?
Tanto el uso de ChatGPT como de todo la integración con ChatGPT son GRATUITOS. Que sea gratis para el usuario no significa que no tenga un coste. Lo tiene. A veces bastante. Todo ese coste lo estoy asumiendo yo. Cada consulta me cuesta dinero. He optimizado al máximo cada consulta y petición a ChatGPT para que sea el menor posible pero aún así, es un coste. Vamos, que me está costando las perras.
Me sería de gran ayuda que si conocieras a alguien, particular o empresa, que pudiera estar interesado en patrocinar la página de Oficius junto a la integración con ChatGPT, le dijeras que se pusiera en contacto conmigo para ver si podemos llegar a un acuerdo. Amos, venga, que no te cuesta nada, así no me arruino la vida y me ayudas a mantener el servicio. Muchas gracias por adelantado.
Si necesitas más información, me puedes escrbir a mpijierro@gmail.com para esto o para cualquier otra cosa, estaré encantado de contestarte.
Corto y cambio
Bastante mérito tiene si has llegado hasta aquí, muchas gracias nuevamente.
Me despido, de momento. Cualquier comentario, sugerencia o mejora, no dudes en decírmelo. Aquí un poco más arriba tienes mi dirección de email.
Chimpún.
Espacio para la publicidad personal.
Si has llegado a este artículo desde más allá de Orión, te cuento que soy Manu Pijierro,
un desarrollador de aplicaciones web especializado en la creación de soluciones personalizadas para empresas como ERPs y CRMs.
Si necesitas algún tipo de software a medida o crees que te puedo ayudar de alguna forma no dudes en ponerte en contacto conmigo escribiéndome al
correo electrónico mpijierro@gmail.com. Si no puedo yo, intentaré ponerte en contacto con alguien que sí pueda ayudarte.
Prometido.
Además, si te ha gustado este artículo, tengo escritos muchos más sobre los más variopintos temas. Aquí tienes algunos...